Tutorial 2: Introduction to PyTorch
# 이전내용
class XORDataset(data.Dataset):
def __init__(self, size, std=0.1):
"""
Inputs:
size - Number of data points we want to generate
std - Standard deviation of the noise (see generate_continuous_xor function)
"""
super().__init__()
self.size = size
self.std = std
self.generate_continuous_xor()
def generate_continuous_xor(self):
# Each data point in the XOR dataset has two variables, x and y, that can be either 0 or 1
# The label is their XOR combination, i.e. 1 if only x or only y is 1 while the other is 0.
# If x=y, the label is 0.
data = torch.randint(low=0, high=2, size=(self.size, 2), dtype=torch.float32)
label = (data.sum(dim=1) == 1).to(torch.long)
# To make it slightly more challenging, we add a bit of gaussian noise to the data points.
data += self.std * torch.randn(data.shape)
self.data = data
self.label = label
def __len__(self):
# Number of data point we have. Alternatively self.data.shape[0], or self.label.shape[0]
return self.size
def __getitem__(self, idx):
# Return the idx-th data point of the dataset
# If we have multiple things to return (data point and label), we can return them as tuple
data_point = self.data[idx]
data_label = self.label[idx]
return data_point, data_label1. 이어서 쓰는 내용
이전 내용에 이어서 써보고자 한다.
dataset = XORDataset(size=200)
print("Size of dataset:", len(dataset))
print("Data point 0:", dataset[0])
Size of dataset: 200
Data point 0: (tensor([0.9632, 0.1117]), tensor(1))
이전강의에서 얘기했던 __len__ 을 통한 len(dataset) 기능과
__getitem__를 통한 slicing기능이 class type에 적용된 것을 볼 수 있다.
이외에 class의 flow는 size=200을 변수로 넣어줘서,
def __init__ 함수에서 설정해 놓은 self.size = 200으로 저장이 되고
def __init__(self, size, std=0.1):
"""
Inputs:
size - Number of data points we want to generate
std - Standard deviation of the noise (see generate_continuous_xor function)
"""
super().__init__()
# 여기 size=200으로 전체 class에 저장이 된다.
self.size = size
self.std = std
self.generate_continuous_xor()
def genertate_continuous_xor(self)로 코드가 흘러가 위에서 self 상속으로 공유된 변수가 적용된다.
def generate_continuous_xor(self):
# 하단의 size=(self.size, 2)로 parameter가 설정된다. -> 200,2 짜리 tensor생성
data = torch.randint(low=0, high=2, size=(self.size, 2), dtype=torch.float32)
label = (data.sum(dim=1) == 1).to(torch.long)
# To make it slightly more challenging, we add a bit of gaussian noise to the data points.
data += self.std * torch.randn(data.shape)
self.data = data
self.label = label
여기까지가 간단한 모델의 Dataset개요이고, Python을 하면 Data를 visualization 시킬 줄 알면 최고다.
그래서 예제를 보면 우리가 만든 모델을 visualize 하는 기능을 보여준다.
def visualize_samples(data, label):
if isinstance(data, torch.Tensor):
data = data.cpu().numpy()
if isinstance(label, torch.Tensor):
label = label.cpu().numpy()
data_0 = data[label == 0]
data_1 = data[label == 1]
plt.figure(figsize=(4,4))
plt.scatter(data_0[:,0], data_0[:,1], edgecolor="#333", label="Class 0")
plt.scatter(data_1[:,0], data_1[:,1], edgecolor="#333", label="Class 1")
plt.title("Dataset samples")
plt.ylabel(r"$x_2$")
plt.xlabel(r"$x_1$")
plt.legend()
왜 이렇게 보여주나 여러 번 이해해 보려 했는데, 아무리 봐도 별다른 의미가 없었다.
일단 데이터를 가시화한다는 것이 유용한 스킬이라는 것만 알아두고 넘어간다.

2. data.DataLoader
이제부터 딥러닝에서 중요한 파트가 된다.
nn.Sequential(Conv2 d...) 같은 모델을
수학적 개념을 익히고 사용하는 것도 중요하지만,
Data를 어떻게 미리 세팅해 놓을 것인가 또한 매우 매우 매우 매 우 중요하다.
무엇보다 어디서 가져온 모델의 Data포맷이 내가 측정한 Data 포맷과 동일한지 파악해야
제대로 작동하므로, Data 부분은 좀 빠삭하게 익혀둘 필요가 있다고 생각한다.
일단 쭉 훑어보고 해설해보도록 하자.
data_loader = data.DataLoader(dataset, batch_size=8, shuffle=True)
# next(iter(...)) catches the first batch of the data loader
# If shuffle is True, this will return a different batch every time we run this cell
# For iterating over the whole dataset, we can simple use "for batch in data_loader: ..."
data_inputs, data_labels = next(iter(data_loader))
# The shape of the outputs are [batch_size, d_1,...,d_N] where d_1,...,d_N are the
# dimensions of the data point returned from the dataset class
print("Data inputs", data_inputs.shape, "\n", data_inputs)
print("Data labels", data_labels.shape, "\n", data_labels)Data inputs torch.Size([8, 2])
tensor([[-0.0890, 0.8608],
[ 1.0905, -0.0128],
[ 0.7967, 0.2268],
[-0.0688, 0.0371],
[ 0.8732, -0.2240],
[-0.0559, -0.0282],
[ 0.9277, 0.0978],
[ 1.0150, 0.9689]])
Data labels torch.Size([8])
tensor([1, 1, 1, 0, 1, 0, 1, 0])2-1) DataLoader

import torch as t
import torch.utils.data as data
from torch.utils.data import TensorDataset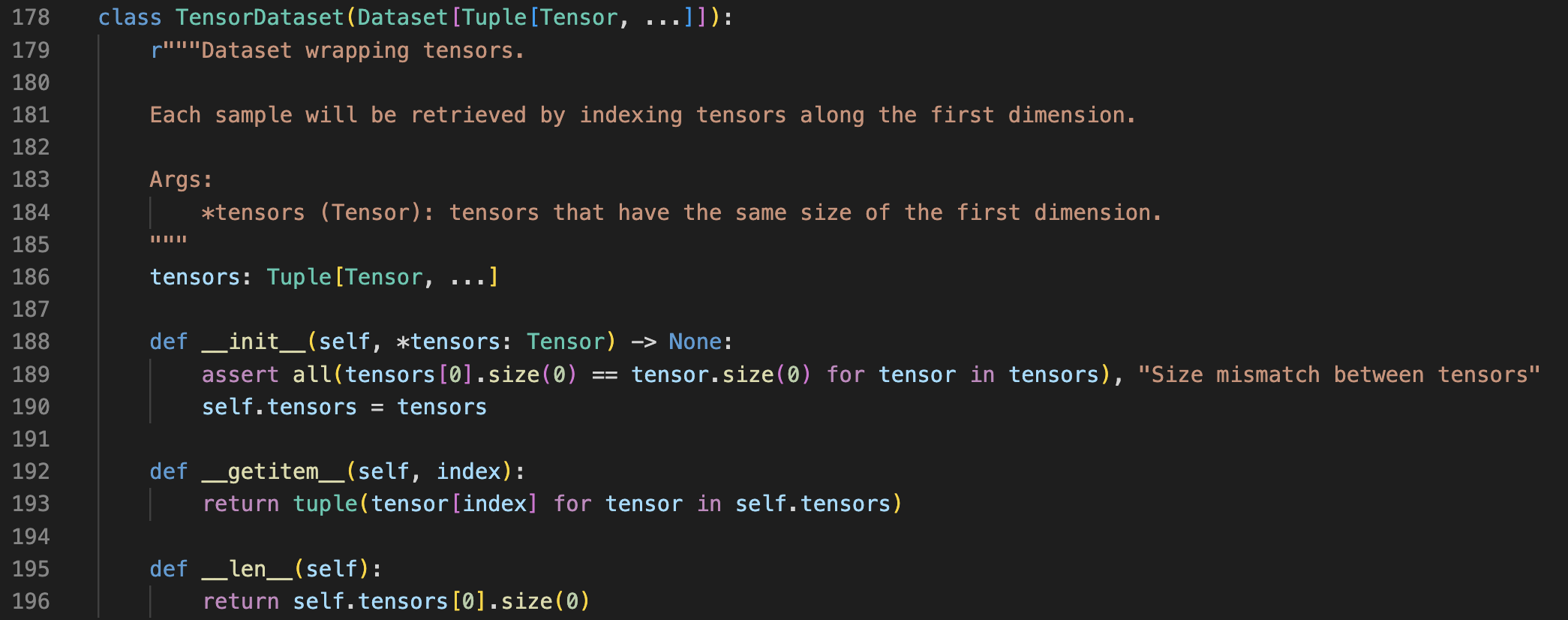
잘 보면, 이전에 XORDataset의 class를 짜면서 만들었던, __getitem__, __len__ 메서드가 있는 것을 확인할 수 있다.
즉, 그냥 XORDataset의 기능을 data의 TensorDataset 라이브러리에서 제공하고 있고,
이를 통해 예제를 만들었다 생각하면 된다.
(그냥 그렇구나)
그러고 나서 임의의 data를 만들어 보자.
data_ = t.arange(0,600).view(12,2,5,5)
# randint(시작,끝,(size))
labels = t.randint(1,100,(12,))
print(data_)
print(labels)
1) data_ = t.arrange(0,600). view(12,2,5,5)
0~599까지 총 600개의 숫자를 tensor에 저장하고,
추가적인 팁이 있다면, view(Batch, Channel, Height, Width) = (N, C, H, W)라고 불린다. (N은 아마 Number of Batch이지 않을까)
Tensor flow와 PyTorch의 Size 명칭 위치가 조금 다른 거로 알고 있으니, Framework을 바꾸게 된다면 꼭 잊지 말자.
2) labels = t.randint(1,100, (12,))
이제 data에 맞는 label의 랜덤 한 개수를 만들어준다, DataLoader를 이해하기 위한 예제이기에 크게 의미 없다.
그냥 뒤에 적힌 (12,)로 사이즈만 맞춘다고 보자.
# Must match the size[0] between data & labels
dataset = TensorDataset(data_, labels)
# 600개의 데이터에서 labels를 12개로 나눴기 때문에, 50개의 데이터가 총 12번씩 보이게 된다. (600/12 = 50)
# 최종적으로는 (50,1) x 12 => (data set, 레이블) x Batch 개의 세트가 나온다.
# 맨 아래의 tensor는 label을 뜻한다.
# 아래는 (50,1), (50,1), (50,1) ... 총 12개의 세트중 한개의 data set을 보여주는 것이고
# next(iter(dataset))은 data set을 한개씩 보여주는 역할을 한다.
print(next(iter(dataset)))(tensor([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]],
[[25, 26, 27, 28, 29],
[30, 31, 32, 33, 34],
[35, 36, 37, 38, 39],
[40, 41, 42, 43, 44],
[45, 46, 47, 48, 49]]]),
tensor(81))
3) dataset = TensorDataset(data_, labels)
내가 만든 data와 label을 하나의 tensor묶음으로 만드는 형태이다.
텐서묶음(data, labels, 어쩌고, 저쩌고,... )처럼 쭉 이어서 만들 수도 있다.
단순히 XORDataset이랑 같은 기능을 하는 파트다. (__len__, __getitem__ 같은 __method__들이 추가된 class)
4) next(iter(dataset))
DataLoader class는 일반적인 방법으로는 어떻게 data들이 정리 돼 있는지, 내부를 들여다볼 수가 없는데
내 Data가 올바르게 잘 정리 돼 있는지 궁금하다면
next(iter(dataset))으로 한 개의 Batch를 뜯어볼 수 있다.
코드에 설명해 놓았듯,
data_의 size는 현재 (12, 2, 5, 5)이므로, BatchSize가 12이고 (2*5*5)의 Tensor 묶음이 있다는 뜻이다.
묶음 중에 앞에서부터 하나씩 보고 싶어서 순서대로 차례로 본다 그래서 next를 쓰고,
반복 가능한 type들을 분해해주는 iter를 활용해서 TensorDataset을 for문처럼 해체해 준것이다.그러면 위에 출력값처럼 (50개의 Data, 1개의 Label) 형식으로 나오게 된다.
이제, 배우고자하는 DataLoader에 우리가 만든 TensorDataset을 넣어보자.
# Size = (12,2,5,5)
# Size[0]/batch_size 갯수만큼 data set가 나오게 된다.
dataloader = data.DataLoader(dataset, batch_size=4, shuffle=True)5) data.DataLoader(dataset, batch_size=4, shuffle=True)
우리가 만든 dataset을
batchsize=4로 또 나누고,
shuffle=True 마구마구 섞어버린다는 아주 간단한 의미이다.
이러면 당연히 (12,2,5,5) -> (4,2,2,5), (4,2,2,5), (4,2,2,5) 이렇게 3개로 나눠진다는 간단한 의미다.
만일 batchsize = 3이라면, (4,2,2,5) x 4이 되는 거다.
확인을 위해 뜯어보자.
어마무시한 길이인데, 정확히 보기 위해 전부다 출력해봤다.
Batch 0,1,2 총 3개가 나오고 전부 size가 (4,2,5,5)인 것을 확인할 수 있다.
그리고 그에 따른 Label이 Batch Number (=4)에 맞게 4개씩 출력되는 걸 볼 수 있고,
마지막으로 0~599까지 순서대로 있던 Tensor 묶음들이
Channel 단위로 shuffle=True 된 걸 확인할 수 있다.
for i, (batch,labelss) in enumerate(dataloader):
print(f"{i}".center(100,"="))
print("Batch size : ", batch.size())
print("Batch : ", batch)
print("labels size : ", labelss.size())
print("Labels : ", labelss)
print(f"Finish".center(100,"="))
print("Total Batch Sets : ", i + 1)=================================================0==================================================
Batch size : torch.Size([4, 2, 5, 5])
Batch : tensor([[[[400, 401, 402, 403, 404],
[405, 406, 407, 408, 409],
[410, 411, 412, 413, 414],
[415, 416, 417, 418, 419],
[420, 421, 422, 423, 424]],
[[425, 426, 427, 428, 429],
[430, 431, 432, 433, 434],
[435, 436, 437, 438, 439],
[440, 441, 442, 443, 444],
[445, 446, 447, 448, 449]]],
[[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[ 10, 11, 12, 13, 14],
[ 15, 16, 17, 18, 19],
[ 20, 21, 22, 23, 24]],
[[ 25, 26, 27, 28, 29],
[ 30, 31, 32, 33, 34],
[ 35, 36, 37, 38, 39],
[ 40, 41, 42, 43, 44],
[ 45, 46, 47, 48, 49]]],
[[[550, 551, 552, 553, 554],
[555, 556, 557, 558, 559],
[560, 561, 562, 563, 564],
[565, 566, 567, 568, 569],
[570, 571, 572, 573, 574]],
[[575, 576, 577, 578, 579],
[580, 581, 582, 583, 584],
[585, 586, 587, 588, 589],
[590, 591, 592, 593, 594],
[595, 596, 597, 598, 599]]],
[[[500, 501, 502, 503, 504],
[505, 506, 507, 508, 509],
[510, 511, 512, 513, 514],
[515, 516, 517, 518, 519],
[520, 521, 522, 523, 524]],
[[525, 526, 527, 528, 529],
[530, 531, 532, 533, 534],
[535, 536, 537, 538, 539],
[540, 541, 542, 543, 544],
[545, 546, 547, 548, 549]]]])
labels size : torch.Size([4])
Labels : tensor([80, 81, 3, 46])
=================================================1==================================================
Batch size : torch.Size([4, 2, 5, 5])
Batch : tensor([[[[350, 351, 352, 353, 354],
[355, 356, 357, 358, 359],
[360, 361, 362, 363, 364],
[365, 366, 367, 368, 369],
[370, 371, 372, 373, 374]],
[[375, 376, 377, 378, 379],
[380, 381, 382, 383, 384],
[385, 386, 387, 388, 389],
[390, 391, 392, 393, 394],
[395, 396, 397, 398, 399]]],
[[[250, 251, 252, 253, 254],
[255, 256, 257, 258, 259],
[260, 261, 262, 263, 264],
[265, 266, 267, 268, 269],
[270, 271, 272, 273, 274]],
[[275, 276, 277, 278, 279],
[280, 281, 282, 283, 284],
[285, 286, 287, 288, 289],
[290, 291, 292, 293, 294],
[295, 296, 297, 298, 299]]],
[[[450, 451, 452, 453, 454],
[455, 456, 457, 458, 459],
[460, 461, 462, 463, 464],
[465, 466, 467, 468, 469],
[470, 471, 472, 473, 474]],
[[475, 476, 477, 478, 479],
[480, 481, 482, 483, 484],
[485, 486, 487, 488, 489],
[490, 491, 492, 493, 494],
[495, 496, 497, 498, 499]]],
[[[150, 151, 152, 153, 154],
[155, 156, 157, 158, 159],
[160, 161, 162, 163, 164],
[165, 166, 167, 168, 169],
[170, 171, 172, 173, 174]],
[[175, 176, 177, 178, 179],
[180, 181, 182, 183, 184],
[185, 186, 187, 188, 189],
[190, 191, 192, 193, 194],
[195, 196, 197, 198, 199]]]])
labels size : torch.Size([4])
Labels : tensor([51, 12, 63, 99])
=================================================2==================================================
Batch size : torch.Size([4, 2, 5, 5])
Batch : tensor([[[[ 50, 51, 52, 53, 54],
[ 55, 56, 57, 58, 59],
[ 60, 61, 62, 63, 64],
[ 65, 66, 67, 68, 69],
[ 70, 71, 72, 73, 74]],
[[ 75, 76, 77, 78, 79],
[ 80, 81, 82, 83, 84],
[ 85, 86, 87, 88, 89],
[ 90, 91, 92, 93, 94],
[ 95, 96, 97, 98, 99]]],
[[[100, 101, 102, 103, 104],
[105, 106, 107, 108, 109],
[110, 111, 112, 113, 114],
[115, 116, 117, 118, 119],
[120, 121, 122, 123, 124]],
[[125, 126, 127, 128, 129],
[130, 131, 132, 133, 134],
[135, 136, 137, 138, 139],
[140, 141, 142, 143, 144],
[145, 146, 147, 148, 149]]],
[[[300, 301, 302, 303, 304],
[305, 306, 307, 308, 309],
[310, 311, 312, 313, 314],
[315, 316, 317, 318, 319],
[320, 321, 322, 323, 324]],
[[325, 326, 327, 328, 329],
[330, 331, 332, 333, 334],
[335, 336, 337, 338, 339],
[340, 341, 342, 343, 344],
[345, 346, 347, 348, 349]]],
[[[200, 201, 202, 203, 204],
[205, 206, 207, 208, 209],
[210, 211, 212, 213, 214],
[215, 216, 217, 218, 219],
[220, 221, 222, 223, 224]],
[[225, 226, 227, 228, 229],
[230, 231, 232, 233, 234],
[235, 236, 237, 238, 239],
[240, 241, 242, 243, 244],
[245, 246, 247, 248, 249]]]])
labels size : torch.Size([4])
Labels : tensor([95, 35, 88, 68])
===============================================Finish===============================================
Total Batch Sets : 3
끊어가기
거의 뭐 맨날 끊어가서 어느 세월에 다하나 싶긴 한데,
복습도 생각보다 시간을 많이 잡아먹다 보니, 다른 공부에 지장이 생겨 적당히 해야겠다는 생각이 든다.
아무튼 이제 슬슬 기초단계는 마무리가 된다.
이다음에는 딥러닝의 꽃인 optimization과 Loss modules이 등장한다. 아디오스
'Deep Learning Study' 카테고리의 다른 글
| Paper 구현하고 싶다. #1-5 Optimization & Loss Modules & Training (1) | 2023.02.26 |
|---|---|
| Paper 구현하고 싶다. #1-3 PyTorch FrameWork (0) | 2023.02.07 |
| Paper 구현하고 싶다. #1-2 Introduction to Pytorch (1) | 2023.01.30 |
| Paper 구현하고 싶다. #1-1 Introduction to Pytorch (0) | 2023.01.28 |
| Paper 구현하고 싶다. #0 기초 다지기 (학습계획) (0) | 2023.01.20 |



