1. Pytorch 알아보기
Tutorial 2: Introduction to PyTorch — UvA DL Notebooks v1.2 documentation
Tutorial 2: Introduction to PyTorch Welcome to our PyTorch tutorial for the Deep Learning course 2022 at the University of Amsterdam! The following notebook is meant to give a short introduction to PyTorch basics, and get you setup for writing your own neu
uvadlc-notebooks.readthedocs.io
굉장히 기본적인 내용 같지만, 생각 이상으로 얻어갈 지식들이 많은 Tutorial이다.
딥러닝에 필요한 정보만 쏙쏙 빼기 앞서, 다른 Libraries에 대한 설명들은 아주아주 간략하게 설명하려고 한다.
딥러닝을 공부할 정도면, 사실 가상환경(venv or anaconda)이나, 필요한 라이브러리, Jupyternotebook에 대한 설명은
딱히 하지 않아도 잘 알아 들을 수 있을 거라 믿는다.
이런 부분을 궁금하고 또 찾아보고 싶을 땐,
ChatGPT에 검색해 보거나, Google에 'python + "라이브러리 이름"' 이런 식으로
검색해 예제를 풀어보는 걸 추천한다.
2. The Basics of PyTorch
import torch
print("Using torch", torch.__version__)
사용 중인 torch version을 체크한다.
Using torch 1.13.0
그리고 이어서 seed 환경을 고정적으로 만들어준다.
torch.manual_seed(42) # Setting the seed
이는 딥러닝의 특성상, 모델 training을 할 때마다, 결괏값이 달라지게 되면
내가 짠 코드가 얼마나 효율적인지 비교를 하기 힘들기 때문에,
PyTorch에서 stochastic 한 random numbers를 생성하는 함수를 고정적으로 사용한다는 뜻이다.
위 과정을 통해서 우리는, 적당히 랜덤 하게 잘 분포된 숫자들을 가지고
내가 짠 코드의 성능을 진단할 수 있게 된다.
3. Tensors
Tensor는 흔히 차원의 개념으로 이해하면 쉽다.
이런 차원을 n차원까지 늘려서 5,6,7,... 차원이라는 개념으로 Tensor를 이해하면 된다.
공학적인 측면에서 다루는 Tensor와 딥러닝에서 다루는 Tensor의 개념이 조금 다른 것으로 알고 있는데,
둘 다 공부해 본 입장에서는 사실 큰 차이를 못 느끼겠다. (t를 torch로 바꿔주세오)
# t.Tensor(차원의 갯수)
>>> t.Tensor(1) # 1D-Dimension
tensor([0.])
>>> t.Tensor(2,1) # 2D-Dimension
tensor([[ 0.0000e+00],
[-1.0842e-19]])
>>> t.Tensor(3,1,1) # 3D-Dimension
tensor([[[2.0000e+00]],
[[3.1710e-05]],
[[0.0000e+00]]])참고로 (1,1,1) = 3차원이다, index 개수에 따라 차원이 정해지는 거지 맨 앞자리의 숫자랑은 관려없다.
그냥 가시성을 위한 예시를 들어봤다.
중점적으로 볼 건 맨 앞 ' [ ' 과 맨뒤 ' ] ' 의 의 개수이다.
4. Operations
이제 PyTorch에서 주로 사용하게 연산 기법을 알아보자.
(1) 연산 (add_)
이는 논문, 수식 등을 보고 모델을 만드는데 주로 쓰이게 된다.
x1 = torch.rand(2, 3)
x2 = torch.rand(2, 3)
y = x1 + x2
print("X1", x1)
print("X2", x2)
print("Y", y)
X1 tensor([[0.1053, 0.2695, 0.3588],
[0.1994, 0.5472, 0.0062]])
X2 tensor([[0.9516, 0.0753, 0.8860],
[0.5832, 0.3376, 0.8090]])
Y tensor([[1.0569, 0.3448, 1.2448],
[0.7826, 0.8848, 0.8151]])
근데, 굳이 y라는 변수를 따로 지정하지 않고, x2에 x1을 더하는 방법도 있다.
이런 방법을 이 Tutorial에서는 애용할 예정이다. (아래)
x1 = torch.rand(2, 3)
x2 = torch.rand(2, 3)
print("X1 (before)", x1)
print("X2 (before)", x2)
x2.add_(x1)
print("X1 (after)", x1)
print("X2 (after)", x2)
X1 (before) tensor([[0.5779, 0.9040, 0.5547],
[0.3423, 0.6343, 0.3644]])
X2 (before) tensor([[0.7104, 0.9464, 0.7890],
[0.2814, 0.7886, 0.5895]])
X1 (after) tensor([[0.5779, 0.9040, 0.5547],
[0.3423, 0.6343, 0.3644]])
X2 (after) tensor([[1.2884, 1.8504, 1.3437],
[0.6237, 1.4230, 0.9539]])
(2) 차원 변환 (size, view, permute)
딥러닝을 하다 보면, size(shape)를 자유자재로 변환시키는 능력이 필요하다.
이를 위해 간단한 tensor X를 만들어보자.
x = torch.arange(6)
print("X", x)X tensor([0, 1, 2, 3, 4, 5])
(2-1) size() & shape
이렇게 만들어진 X tensor는 (1,6)이라는 size(shape)를 갖게 된다.
tensor의 size가 궁금하다면
# 사이즈가 궁금할때
print(x.size())
# 다른방법
print(x.shape)# 둘다 동일하게 6으로 나온다.
torch.Size([6])(2-2) view()
그럼 이 size를 자유자재로 변경시켜 보자
x = x.view(2, 3)
print("X", x)X tensor([[0, 1, 2],
[3, 4, 5]])
view도 위에서 언급한 add_처럼 굉장히 자주 등장하는 function이다.
위에서 X tensor가 0,1,2,3,4,5로 쭉 늘어졌는데, (1행 6열 = 1x6)
이를
0,1,2
3,4,5
(2행 3열 = 2x3)로 바꾼 것이다.
굉장히 간단한 내용이니 시각적으로 확인만 하고,
추후에 이런 내용들이 많을 것이다 정도로 이해만 하면 된다.
(2-3) permute()
차원 (C, H, W) = (0,1,2) 간 Swap을 하고 싶다면 permute() 함수를 사용한다.
더 많은 n차원도 가능하지만, 대표적인 Channel(C), Height(H), Width(W) 3차원인 경우를 예시로 들어보겠다.
xt = torch.rand(3,2,4)
print("xt")
print(xt.size())
print(xt)
xp = x.permute(2,0,1) #(4,3,2)
print("xp")
print(xp.size())
print(xp)(3,2,4)
3 Channel(C)
2 Height(H)
4 Width(W)
3 채널, 2행, 4열짜리 랜덤 텐서를 만든다.
여기서 사이즈가 (3,2,4)인 xt Tensor의
첫 번째 차원 숫자는 '3(C)'이 된다.
즉 첫 번 째니까 0이 된다.
(파이썬 프로그램은 0부터 카운팅을 시작함)
같은 원리로
2번째 자리에 있는 '2(H)'는 1이 되겠고
3번째 자리에 있는 '4(W)'는 2가 되겠다.
그래서 permute에서 써져 있는 (2,0,1)은
(C, H, W) -> (W, C, H)의 순서로 바꾼다는 뜻이다.
xt
torch.Size(3,2,4)
tensor([[[0.5686, 0.2860, 0.2736, 0.0084],
[0.3762, 0.5472, 0.9655, 0.6961]],
[[0.8459, 0.6332, 0.3099, 0.4172],
[0.8102, 0.6680, 0.8839, 0.3261]],
[[0.5609, 0.8179, 0.9705, 0.1916],
[0.0444, 0.0342, 0.9344, 0.8231]]])
xp
torch.Size(4,3,2)
tensor([[[0.5686, 0.3762],
[0.8459, 0.8102],
[0.5609, 0.0444]],
[[0.2860, 0.5472],
[0.6332, 0.6680],
[0.8179, 0.0342]],
[[0.2736, 0.9655],
[0.3099, 0.8839],
[0.9705, 0.9344]],
[[0.0084, 0.6961],
[0.4172, 0.3261],
[0.1916, 0.8231]]])5. Indexing
파이썬에서 가장 중요하다고 볼 수 있는, Indexing이다.
물론 숙련된 사람들은 굳이 이 파트를 읽을 필요는 없지만,
난 아니라서 복습 겸으로 한번 해보고자 한다.
row는 Size에서 Height의 개념과 유사하고
column은 Size에서 Width와 개념이 유사하다.
x = torch.arange(12).view(3, 4)
print("X", x)
X tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
print(x[:, 1]) # Second column
x Tensor에서,
' : ' = 전체 row(H)에서,
' 1 ' = 2번째 column(W)을 가져온다는 뜻이다.

이러면 겹치는 부분이 [1,5,9]가 된다.
tensor([1, 5, 9])print(x[0]) # First row
x Tensor에서,
' 0 ' = 첫 번째 row(H)에서
가져온다는 뜻이다.
뒤에 추가적인 문구가 없으면
위에서 언급한
' : ' 와 같이 전체(W)의 의미를 갖는다.
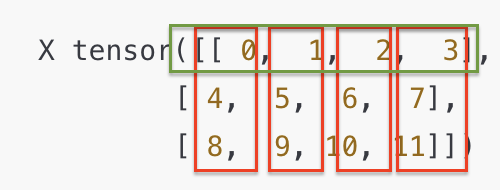
이러면 겹치는 부분은 [0,1,2,3] 이 된다.
tensor([0, 1, 2, 3])
print(x[:2, -1]) # First two rows, last column
-1은 맨 뒤에서부터 숫자를 세는 방식이니까
' :2 ' = row 2번째 자리 이전
' -1 '= column 뒤에서 첫 번째

이러면 겹치는 부분은 [3,7]이다.
tensor([3, 7])
끊어 가기
생각보다 글이 너무 길어져서 끊어가려고 한다.
그다음 내용부터 갑자기 수식이 마구마구 등장하기 때문에,
한번 끊고 다음에 다시 업로드해보겠다.
'Deep Learning Study' 카테고리의 다른 글
| Paper 구현하고 싶다. #1-5 Optimization & Loss Modules & Training (1) | 2023.02.26 |
|---|---|
| Paper 구현하고 싶다. #1-4 data.DataLoader (0) | 2023.02.16 |
| Paper 구현하고 싶다. #1-3 PyTorch FrameWork (0) | 2023.02.07 |
| Paper 구현하고 싶다. #1-2 Introduction to Pytorch (1) | 2023.01.30 |
| Paper 구현하고 싶다. #0 기초 다지기 (학습계획) (0) | 2023.01.20 |



