Tutorial 2: Introduction to PyTorch
1. Intro
오늘 할 내용은 사실 딥러닝 프레임 워크 친숙해지기,
좀 더 나은 알고리즘 탐방하기 쪽에 더 가깝다.
XOR 알고리즘은 전기 신호 배우면서 나오는 논리회로 이런 느낌인데
뒷내용에 대입해 보자면 그 내용은 사실 안 중요하다.
단지 볼 부분은 코드 flow와 딥러닝 framework이 어떻게 형성되는지
정도 아는 게 중요하다.
2. Learning by example: Continuous XOR
기본적인 Libraries부터 불러오는데,
import torch.nn as nn
import torch.nn.functional as F
nn과 functional as F를 다양한 오픈소스에서 볼 수 있다.
nn과 F의 차이점으로는 사실 편의 차이로 많이 구분하는데,
좀 더 들어가면 F를 활용한 CrossEntropyLoss는 원하는 weight를
Control 하고자 할 때 사용한다고는 하는데,
이게 방대한 데이터를 다루는
딥러닝 분야에서 어떤 의미를 갖는지는 살짝 의문이다.
해당 문서에서는 nn만 사용하므로 자세한 설명은 넘어가겠다.
2.1 nn.Module
class MyModule(nn.Module):
def __init__(self):
super().__init__()
# Some init for my module
def forward(self, x):
# Function for performing the calculation of the module.
pass
자주 사용하게 될 PyTorch의 기본 framework이다.
간단하게 설명하면,
MyModule : 추후에 지정하게 될 model, block, layer 등등 다양한 개념을 class로 먼저 만들게 된다.
nn.Module : 내가 만들 모델에 class를 상속시킨다.
def __init__(self) : 함수 def를 만들고 __init__ method를 생성한다. 그리고 self 상속을 한다.
class, self 상속, method 생성은 사실 어느 정도 파이썬을 다뤄봤다는 기준이 된다.
난이도로 치면 한 중급정도는 되지 않을까 싶은데, __어쩌고__ 같은 문법들이 이해가 안 간다면,
마법의 소라고동 chatgpt에게 python method가 뭐냐 물어보고 예제를 달라고 하면 된다.
def forward(self) : class MyModule + ()을 붙여서 호출하면 실행되는 부분이다. ex) Module(inputs)
앞으로 만들 Network에서 항상 적는 부분이고, flow는 추후에 다뤄보자.
2.2 Simple classifier
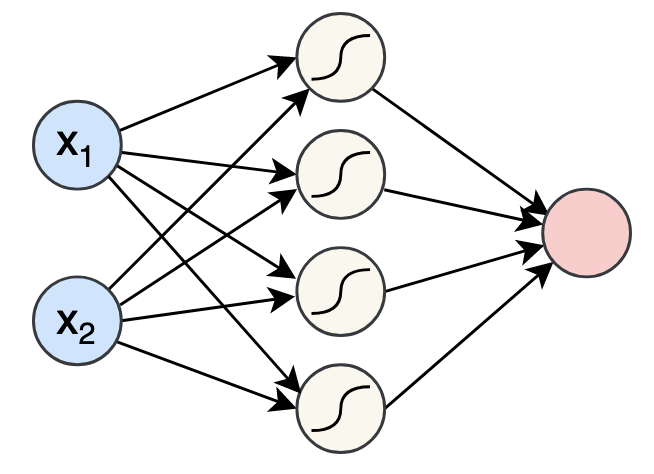
그냥 자주 보이는 그림인데, 요즘은 좀 더 간소하게 네모 박스로 표현하는 편이다.
아무튼, x1, x2는 parameter고 중간에 노란 박스는 activation function을 나타낸다.
그리고 빨간 박스 output으로 끝.
class SimpleClassifier(nn.Module):
def __init__(self, num_inputs, num_hidden, num_outputs):
super().__init__()
# Initialize the modules we need to build the network
self.linear1 = nn.Linear(num_inputs, num_hidden)
self.act_fn = nn.Tanh()
self.linear2 = nn.Linear(num_hidden, num_outputs)
def forward(self, x):
# Perform the calculation of the model to determine the prediction
x = self.linear1(x)
x = self.act_fn(x)
x = self.linear2(x)
return x
Module 상속하고, init으로 inputs 정하고, hidden layer 만들고, output의 개수를 정한다.
그리고 상속한 nn.Module의 parameter를 init으로 초기화시킨다. 그다음에 자동으로 class 내 변수를 만들어 낸다.
self.linear1 = nn.Linear(num_inputs, num_hidden) :파란색 동그라미를 input으로 받고 노란색 동그라미로 out 시킨다.
self.act_fn = nn.Tanh() : activation function을 Tanh()으로 설정
self.linear2 = nn.Linear(num_hidden, num_outputs) : 노란색 동그라미를 input으로 받고 output으로 보낸다.
직관적으로 파란색 -> 노란색 -> 빨간색으로 이어지므로, 각각 영역의 개수에 맞춰 숫자를 input, output을 만든 거다.
이후에 forward(self, x) 파트는 SimpleClassifier() 형식으로 호출했을 때 실행되는 파트다.
그래서 모델을 실행시켜보면,
model = SimpleClassifier(num_inputs=2, num_hidden=4, num_outputs=1)
# Printing a module shows all its submodules
print(model)SimpleClassifier(
(linear1): Linear(in_features=2, out_features=4, bias=True)
(act_fn): Tanh()
(linear2): Linear(in_features=4, out_features=1, bias=True)
)
이렇게 내가 만든 Model의 detail을 볼 수 있다. 그럼 이제 model에서 지나간 parameter들을 확인해 보자.
for name, param in model.named_parameters():
print(f"Parameter {name}, shape {param.shape}")Parameter linear1.weight, shape torch.Size([4, 2])
Parameter linear1.bias, shape torch.Size([4])
Parameter linear2.weight, shape torch.Size([1, 4])
Parameter linear2.bias, shape torch.Size([1])
model이라는 class는 nn.Module을 상속하고 있다.
그리고 nn.Module은. named_parameters라는 self인자를 가지고 있기 때문에, 해당 Module을 뜯어볼 수 있다.
사실 저런 기능이 있는지도 몰랐다. 그래서 내부 알고리즘을 뜯어봤는데, 더 모르겠다.
직관적으로 Model 내부에 학습된 parameter를 가져옵니다는 알 수 있지만,
생판 모르다가 이걸 어떻게 알지라는 생각은,
그냥 많은 예제들을 풀다가 주워가는 키워드로 마음 편하게 받아들이고
공부를 꾸준히 해야겠다는 생각만 든다.
처음 공부 목적이었던, 다양한 알고리즘이 이런 식으로 공부된다고 본다.
2.3 The data & dataset class
이제부터가 진짜 딥러닝의 시작이라고 볼 수 있다.
이미 좋고 많은 모델들이 인터넷에 열려있기 때문에,
데이터를 전처리하고 모델의 인풋 아웃풋만 맞춰주면
손쉽게 돌릴 수 있는 모델들이 상당히 많아서
데이터 전처리에서 갈리는 것이 많다고 한다.
(실은 그렇지만도 않다, 내부 구조를 알아야 제대로 하긴 한다.)
어쨌든 이제부터는 주석을 넣어서 코드를 설명해보고자 한다.
# 1. PyTorch에서 다루기 쉽게 data라는 class를 불러줍니다.
import torch.utils.data as data
# 2. Dataset을 만들자
class XORDataset(data.Dataset):
# 3. 데이터의 사이즈를 정하고 표준편차(standard deviation)를 0.1로 설정합니다.
def __init__(self, size, std=0.1):
# 4. 우리가 코드 짤때 팝업으로 중간중간 나오는 부분이다. 다른 코딩러들을 위해 적는것이 국룰이다.
"""
Inputs:
size - Number of data points we want to generate
std - Standard deviation of the noise (see generate_continuous_xor function)
"""
# 5. super로 상속한 class data.Dataset을 초기화 시키고 size, std를 변수 지정한다.
super().__init__()
self.size = size
self.std = std
# 5-1. Data를 만드는 함수를 class안에서 따로 만들어보자.
self.generate_continuous_xor()
# 6. 여기서 부터는 밑에서 따로 설명 하겠다.
def generate_continuous_xor(self):
# Each data point in the XOR dataset has two variables, x and y, that can be either 0 or 1
# The label is their XOR combination, i.e. 1 if only x or only y is 1 while the other is 0.
# If x=y, the label is 0.
data = torch.randint(low=0, high=2, size=(self.size, 2), dtype=torch.float32)
label = (data.sum(dim=1) == 1).to(torch.long)
# To make it slightly more challenging, we add a bit of gaussian noise to the data points.
data += self.std * torch.randn(data.shape)
self.data = data
self.label = label
def __len__(self):
# Number of data point we have. Alternatively self.data.shape[0], or self.label.shape[0]
return self.size
def __getitem__(self, idx):
# Return the idx-th data point of the dataset
# If we have multiple things to return (data point and label), we can return them as tuple
data_point = self.data[idx]
data_label = self.label[idx]
return data_point, data_label
이제 python 하면서 한번 장벽을 만나는 시기다.
남이 짜놓은 def 알고리즘과 __method__의 사용이다.
하지만 걱정 말자 마법의 소라고동과 내가 있으니.
6-1). def generate_continuous_xor(self)
일단 def generate_continuous_xor(self) 은 정말 랜덤으로 만드는 Dataset이다.
그것도 그냥 이 사람 마음대로 만든 것이다.
그래서 내가 추후에 응용하고 싶다면, 이쪽 코드를 건드려서 Data를 바꿀 수 있는 거다.
간단하게 보자면, data와 label의 관계는 앞으로 딥러닝 모델을 만들면서 계속 나오는 관계이고,
기본적인 알고리즘은 data를 model에 넣어서 label과 cross_entropy를 비교하는 방식이다.
근데 이방식은 나중에 알려주는 걸로 하고, 일단 data와 label을 나눈다는 걸 그렇구나 보자.
(내가 얻은 것 : data, 내가 원하는 것 : label)
data = torch.randint(low에서, high까지, 원하는 size, 실수인지 정수인지) : randint가 뭔지 예제를 풀어보는 게 좋다.
(그냥 임의로 만든 거라 사실 큰 의미 없다. data라는 변수를 만든다 정도 외엔 큰 뜻이 없다.)label = (data.sum(dim=1) ==1). to(torch.long) : 이건 크게 data와 상관관계가 있거나 의미가 있는 구문은 아니다.
단지 boolean문법과 to(다른 포맷)이라는 화려한 문법 조합으로 코딩고수처럼 보이게 하는 이 한 줄이 인상 깊었다.
(추후 딥러닝에는 큰 의미 없지만, 응용할 구석은 많은 한 줄이다.)
6-2) __len__(self) & __get__(self, index) :
처음에는 __method__(메서드함수)만 보면 숨이 턱 막히고 목이 간지러웠으며,
화가 좀 나면서 동시에 나의 무력함에 자책하곤 했다.
하지만 마법의 소라고동님은 모든 걸 알고 계신다.

사실 메서드 함수는 class에 우리가 파이썬에서 흔하게 접했던 기능들을 '추가'하는 개념이다.
위의 예시에서 보면 MyList는 class type일 뿐이다.
무슨 뜻이냐면,

이걸 보면 int는 리스트도 아닌데 첫 번째를 꺼내오란 게 뭔 소리냐 싶다.
class도 똑같다. 일반 class에 [0]로 호출하게 되면 동일한 에러가 나오기 마련,
list도 아닌걸 어떻게 읽으라고?라는 반응이 나온다.

그때 필요한 게 __메서드__ 함수 되시겠다.

이렇듯 class를 list의 index로 읽는 기능을 '추가'해 준 것이다.
여기서 index는 대괄호에 들어가는 숫자 [index]를 뜻한다.
이는 파이썬에서 자동으로 인식하는 부분이니, 특수 문법이 적용된 게 아니다.
같은 이론으로 __len__을 추가하여 len() 기능도 class에 추가시켜준 것이다.
(만일 __len__이 없다면, class에 저장된 list의 개수를 읽을 수 없을 것이다.)
끊기
이번에도 엄청 길어졌다.
개인적으로는 Tutorial 5까지 끝마치고
Convolution을 활용한 Image Network들은 대부분 예제로 풀어본 거 같다.
또 paper 일부분을 보면서, 예제를 보지 않고
조금 예측해서 모델을 생성할 수 있는 정도까지 왔는데,
생각보다(?) 어렵지 않아서 마음이 조금 놓인다.
추후에 kaggle로 연습을 강화시켜보고자 한다.
일단 이어지는 내용은 다음에 또 더 추가적으로 쓰겠다.
'Deep Learning Study' 카테고리의 다른 글
| Paper 구현하고 싶다. #1-5 Optimization & Loss Modules & Training (1) | 2023.02.26 |
|---|---|
| Paper 구현하고 싶다. #1-4 data.DataLoader (0) | 2023.02.16 |
| Paper 구현하고 싶다. #1-2 Introduction to Pytorch (1) | 2023.01.30 |
| Paper 구현하고 싶다. #1-1 Introduction to Pytorch (0) | 2023.01.28 |
| Paper 구현하고 싶다. #0 기초 다지기 (학습계획) (0) | 2023.01.20 |



