#PPO with Cartpole in Pytorch
DRL에서 가장 쉬운 예제 CartPole과 Isaac에 쓰이는 Pytorch & PPO의 주제가 겹쳐 해당하는 예제를 토대로
PPO를 분석해보려 한다.
일단 원본 코드[1]에서는 slow error가 나서 일부 수정을하고,
Rendering 기능이 따로 없어서 내가 조금 편집한 코드를 올려본다.
그리고 코드를 참조하면서 Pytorch지식이 부족한 부분을 Z_Torch_Example로 공부해 봤다.
https://github.com/miercat0424/Cartpolev1-PPO-pytorch/tree/main/My_PPO
GitHub - miercat0424/Cartpolev1-PPO-pytorch: Pytorch PPO for Cartpole Example
Pytorch PPO for Cartpole Example. Contribute to miercat0424/Cartpolev1-PPO-pytorch development by creating an account on GitHub.
github.com
#Code Structure of PPO-Cartpole
1,2. PPO-Memory & ActorNetwork

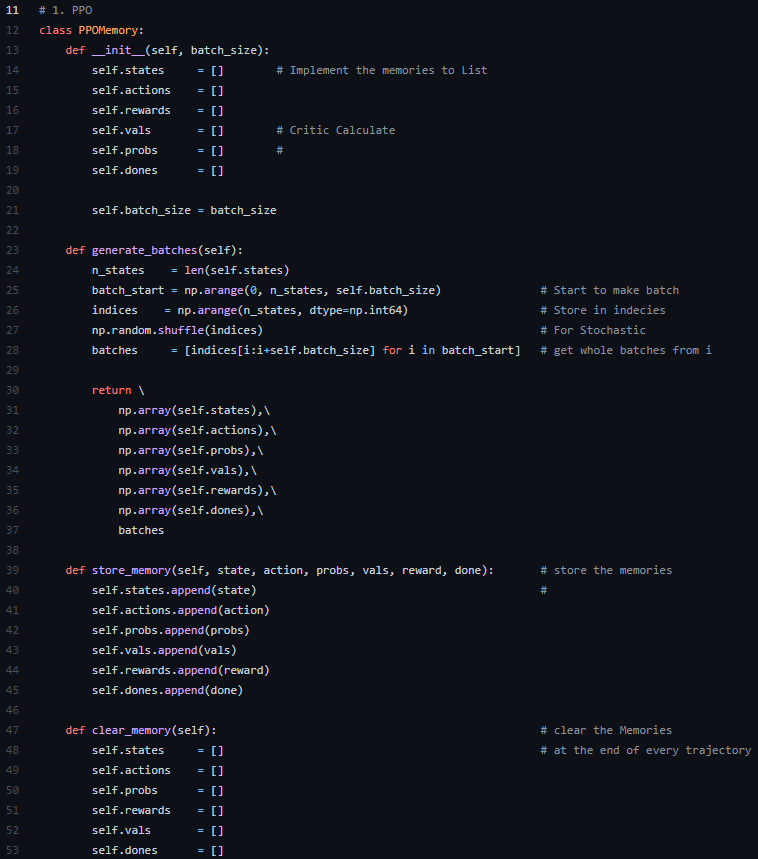
1-1. PPO에서 오가는 데이터들과 Batch를 처리하는 Class를 만들고 Function을 제조한다.
1-2. 영상에서는 pytorch의 list처리 과정에 대한(?) 언급이 조금 있었는데, 이부분은 후에 observation을 받아드리는 부분에서 np.array()를 씌워 개선할 수 있다.
1-3. 그냥 처음부터 self로 np.array([])를 만들면 되지않나 싶은데, 바꿔서 해보니까 학습이 전혀 되질 않았다.
왜그런지는 모르겠다.
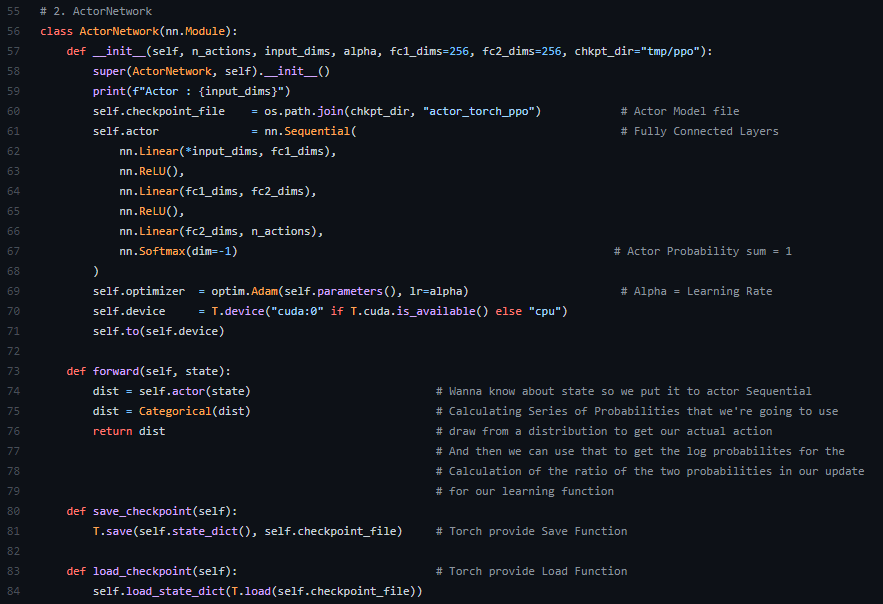
2-1. 단순하게 Fully Connected Network로 이뤄져 있고, 마지막에 SoftMax로 출력하는것이 특징이다.
2-2. Optimizer로는 PPO논문에 기재된 바와같이 성능이 좋은 Adam을 사용한 모습이 보인다.
2-3. foward를 지나면서 state가 들어간다. 환경에서 영향을 받은 Observation의 state(상태)를 Input으로 받아드리는것이 중점이라고 본다.
3. Critic-Network

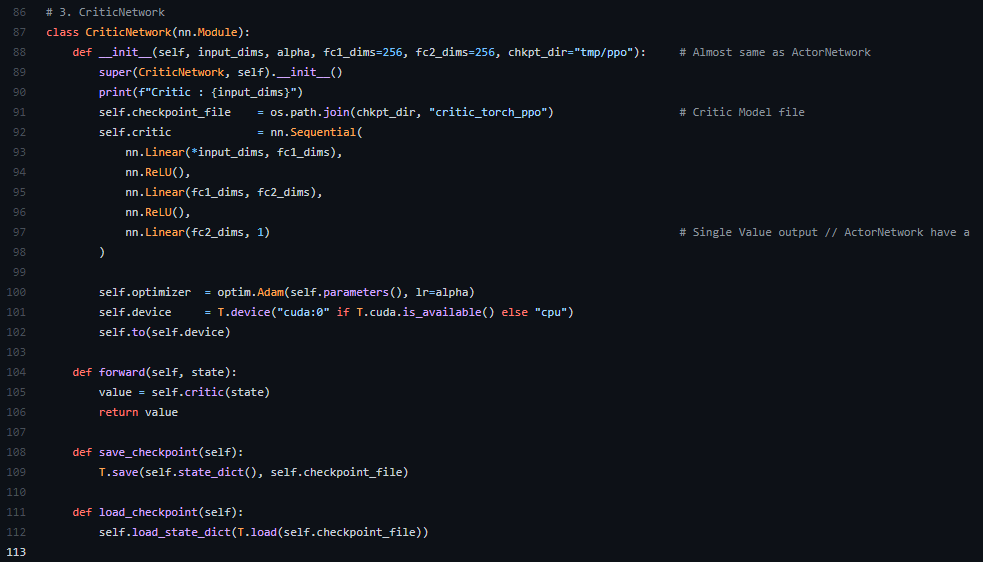
3-1. CriticNetwork에서는 구조가 Actor와 비슷한데 마지막 Ouput에서 Single Value로 빠지는것이 특징이다. Actor Critic을 제대로 공부해본적이 없어서 설명이 힘든데,
π(a|s)에 대한 평가를 내려야 하므로 Single Value값이 나온다고 이해했다. 다양한 value로 값이 도출되면 이에대한 평가가 힘들기 때문에 (exploration이 방대해져서) 라고 이해했다.
일단 내용이 길어져서 한번 끊고 다음 글에서 이어 내려가겠다.
가장 중요한 Agent부분이기 때문에, 코드도 긴 만큼 한번 끊어서 가는게 좋아보인다.
[Reference]
https://www.youtube.com/watch?v=K2qjAixgLqk
GitHub - philtabor/Youtube-Code-Repository: Repository for most of the code from my YouTube channel
Repository for most of the code from my YouTube channel - GitHub - philtabor/Youtube-Code-Repository: Repository for most of the code from my YouTube channel
github.com
영상에 쓰인 원본 코드입니다.



